Introduction
MapReduce是用来处理大数据的一个编程模型。
用户一般规定了map方法来处理一个k/v对,而reduce方法来合并相关的中间值。
Programming Model
计算任务以k/v对的集合作为输入,并产生另外的k/v集合作为输出。用户通过Map和Reduce方法来控制计算。
Map,接受一个k/v对为输入,并产生中间的k/v集合。MapReduce将会以相同的中间的key I来聚合所有相关的值,并把这个集合传递给Reduce方法。
Reduce,接受key I和相关的值,它将这些值进行合并,从而形成一个更小的集合。通常每次Reduce调用会有0到1个输出。
Example
现在我们来统计一个大型文档中的每个单词出现的次数。伪代码如下:
|
|
map方法发出每个单词出现的次数。reduce方法聚合一个单词所有的结果。
Types
用户提供的map和reduce方法大概如下:
map (k1,v1) ! list(k2,v2)
reduce (k2,list(v2)) ! list(v2)
Implementation
Execution Overview
本节描述了在Google广泛使用的一个实现。
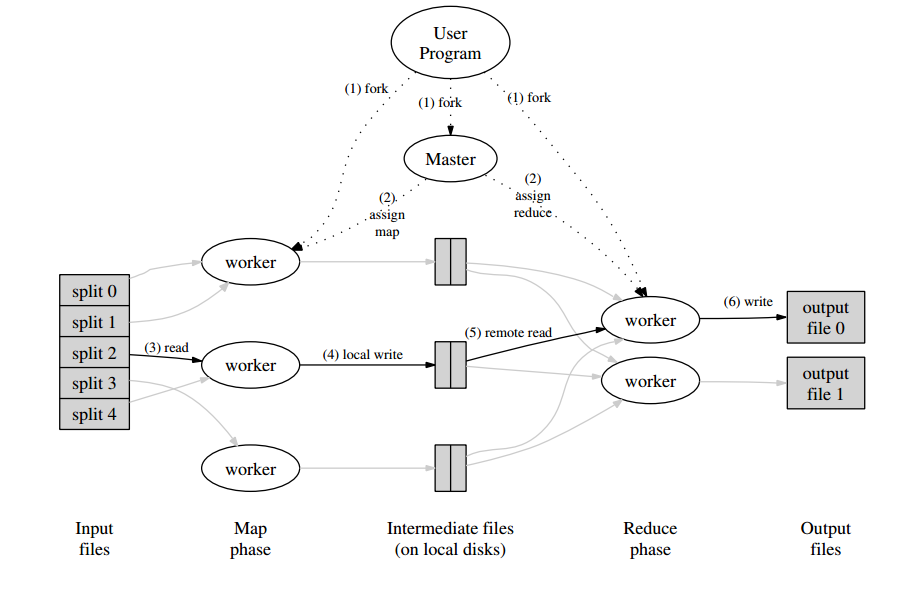
如上图,描述了一个MapReduce操作的整体流程。当一个用户程序调用MapReduce方法,将会发生下列动作:
- MapReduce库首先将会把输入文件切分成M份,每份的大小通常为16M到64M。然后在集群中启动程序。
- 其中有一个程序是master,其余的为workers。workers由master分配任务。总共会分配M个map和R个reduce任务。master会挑选空闲的worker,并给他们分配map或者reduce任务。
- 分配到map任务的worker会读取对应的输入文件的内容。解析出输入数据的k/v对,然后传递给Map方法。map方法生成的K/V中间结果会在内存中缓存。
- 缓存中的数据将会定期被写到本地磁盘上,并划分为R个部分。这些数据保存的位置会被通知给master。
- 当master通知一个reduce worker这些数据保存的位置时,该worker使用RPC调用来读取本地磁盘保存的数据。当reduce worker读取完所有的中间结果时,它会根据key来排序。
- reduce worker迭代所有中间结果,对于每个独一无二的key,它将与这个key对应的集合数据传递给用户定义的Reduce方法。reduce输出的结果会被追加到结果文件中。
- 当所有的map和reduce任务完成,mater唤醒用户程序。然后
MapReduce调用返回结果。
在成功完成之后,mapreduce的执行结果可能会在R个输出文件中。用户通常不需要合并这R个文件,因为,可以把它们作为新的MapReduce的输入数据,或者在别的分布式系统中使用它们。
Master Data Structures
Fault Tolerance
Locality
Task Granularity
Backup Tasks
Refinements
Partitioning Function
Ordering Guarantees
Combiner Function
Input and Output Types
Side-effects
Skipping Bad Records
Local Execution
Status Information
Counters
Performance
略