Raft是什么
Raft是来管理复制日志的一个一致性协议。它和(multi-)Paxos有一样的效果,但是它的结构却和Paxos有所不同。简单点来说,它比Paxos更容易理解,也更容易实现。相信读过Paxos的读者已经体会过Paxos的晦涩、难懂,以及难以实现之处。而Raft直接提出了实现该协议的几个要素:leader选举、日志复制和安全性,甚至给出了伪代码。相比Paxos,Raft通过加强对状态一致性的约束来减少需要考虑的状态数目。
Introduction
一致性算法允许一组机器一起工作来应对某些机器宕机。在过去十来年,Paxos一直在这方面占主导地位:许多实现都是基于Paxos,或受Paxos的影响。但是,Paxos实在是太难懂了,此外,还需要一些复杂的改变来支持实际的应用。
在与Paxos做了一番斗争之后,我们提出了一个新的一致性算法,这个算法就叫Raft,并且它的首先目标就是要容易理解。
Raft有几个特性:
- Strong leader:相比其他协议,Raft对leadership作出了更强的约束,比如说:日志只能从leader流向其他servers。
- Leader election:Raft使用随机的时间来选举leader。
- Membership changes:Raft使用了一个joint consensus方式来应对成员变更。这让整个集群在成员变更期间依然能提供服务。
Replicated state machines
在分布式系统中,使用Replicated state machines来解决各种各样的故障容错问题。
Replicated state machines使用replicated log来实现,每个server存储一系列的commands,这些commands将会被状态机有序执行。每个log都会以相同的顺序存储相同的command。
一致性算法是的工作就是保证replicated log的一致性。
对于一个实际的系统,一致性算法有下列属性:
- safety:不会返回一个错误的结果。
- available: 大多数server可用的情况下,系统就是可用的。
- 不依赖时钟来确保log的一致性
- 当集群中的大多数机器能工作时,少数机器不会影响整个集群的性能。
如下图,是一个Replicated state machines的结构:
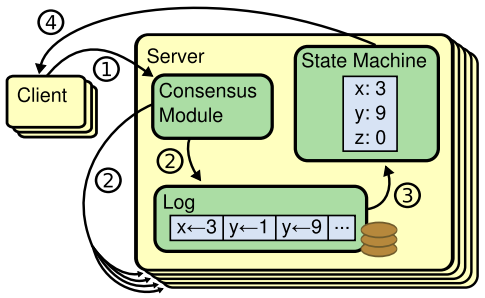
如图所示,一致性算法管理着一个 replicated log,该log包含了来自客户端的状态机命令。不同server的状态机都会从log中执行相同的command序列,所以会输出相同的结果。
What’s wrong with Paxos?
Paxos有两个主要的缺点:
- 第一是Paxos实在是太难懂了。
- 第二是Paxos没有给一个工程实现提供基础。Lamport大师本人对multi-Paxos做了大概的描述,但缺少了很多细节。
Designing for understandability
Raft的几个目标:
- 对于工程实现,提供完整的和实用基础。
- 安全性和可用性
- 高效性
Raft还有一个最最重要的目标:understandability。
Raft采用了两种方式来让读者可理解:
- 问题分解:比如说在Raft中有leader选举、log复制、safty和成员变更。
- 简化状态空间:减少要考虑的状态,比如说log不允许有日志空洞、
The Raft consensus algorithm
Raft首先选举出一个leader,然后让leader来管理复制日志。拥有leader极大的简化了复制日志管理。
通过leader的方式,Raft把一致性问题分解为三个独立的子问题:
- Leader election:必须有个leader。
- Log replication:leader从客户端接受日志,并复制到集群中其他server上。
- Safety:如果一个server应用了一个log entry到它的状态机中,对于相同的log index,其他的server不可能执行不同的command。
Raft basics
集群中的每个server只有三种状态:leader, follower, 或 candidate。正常情况下有一个唯一的leader,其他的server都是follower。follower只能响应leader或candidates的请求,leader处理所有的客户端请求,candidate是用来选举。下图展示了这几种状态之间的转换:
![]()
Raft将时间划分为term,如下图所示。
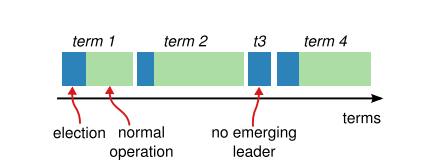
每个term以一次选举开始。如果一个candidate赢得了选举,它就作为剩下term的leader。
term是一个逻辑时钟,每个server都会存储当前的term number,当server之间交换信息的时候,当前的term会被带上。如果一个server的当前term小于其他的server,它就把当前term更新。如果一个candidate或leader发现它的term已经过期,就立刻转换为follower状态。如果一个server收到一个过时的term的请求,则会拒绝这个请求。
Raft使用RPC来互相交流,并且只需要两种RPC请求:
- RequestVote RPC:在选举的时候使用。
- AppendEntries RPC:leader进行日志复制和心跳信息的时候使用。
Leader election
Raft使用心跳机制来触发选举。当一个server启动的时候,它是follower状态,只要server从leader或candidate收到有效的RPC,它就一直保持这种状态。leader定时发送心跳信息给集群中的大多数。如果一个follower在 election timeout时间内没收到信息,它就认为leader宕机,并开始一轮新的选举。
当开始选举的时候,follower增加当前的term,然后转换到candidate状态。然后给自己投票,同时发出一个RequestVote RPC给集群中的其他机器。这个server会一直保持candidate状态,直到发生下列三件事中的一件事:
- 该server赢得了选举
- 其他的server当选为leader
- 一段时间后还是没有选出leader
如果一个candidate在当前term内赢得了集群中大多数的机器的投票,它就当选为leader。在一个给定的term,每个server最多只能投一票,并且按照先谁来救投给谁的原则进行投票。大多数原则保证了在一个term中,最多只能有一个candidate可以赢得选举。
如果在等待投票的时候,一个candidate从别的server收到一个AppendEntries RPC说它是leader,如果leader的term大于或等于当前server的term,该candidate就意识到这个leader是合法的,然后转换到follower状态。如果RPC中的term小于当前server的term,该candidate会拒绝这个PRC,并继续保持candidate状态。
第三种情况发生在一个candidate既没有赢得选举,也没有丢失选举的情况下:如果多个server同时成为了candidate,将不会有candidate赢得大多数。当发生这种情况的时候,每个candidate将会time out,然后开始一轮新的选举。注意的是,如果没有一些额外的措施,可能这种情况会一直重复下去。
Raft使用随机的election timeout来保证不会发生上诉情况。Raft的election time从一个固定区间中(如150-300ms)选择一个值,这样,大多数情况下,只有一个server会time out,然后它赢得选举,并在其他server time out之前发送心跳。
Log replication
一旦一个leader被选举出来,它就开始处理客户端请求。每个客户端请求都会包含一个被状态机执行的command。leader把这个command作为一个新的entry追加到log中,然后同时发送AppendEntries RPCs给其他的server来复制这个entry。当entry被安全的复制之后,leader就会把这个command应用于状态机,然后将执行结果返回给client。如果followers宕机或run slowly,或网络丢包的时候,leader会重试AppendEntries RPCs 直到所有的followers保存了所有的log entries。
Logs像下图一样被组织起来。
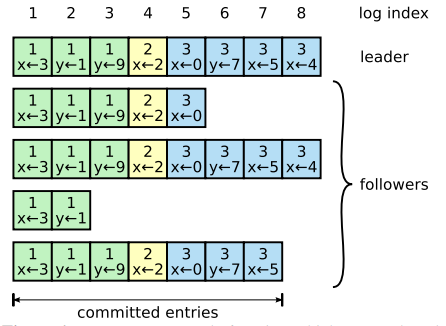
如图所示,Logs由entries组成,每个entry包含它被创建的term,还包含一个command。term用来检查log的不一致。每个log entry也包含一个整数index用来标识他在log中的位置。
leader来决定什么时候把一个log entry应用到状态机上是安全的,这样的entry被称为committed。Raft保证了committed entries是被持久化并最终被所有可用的状态机应用。一个log entry就被committed当创建这个log entry的leader把它复制到到集群中的大多数机器中的时候。这也会commit该leader的log中的之前的entries,包括了之前的leader创建的entries。leader追踪着它知道的已经被committed的entry的最大的index,并在之后的AppendEntries RPCs中带上这个index,一旦一个follower知道一个log entry已经被committed,它就把这个entry应用于状态机。
Raft设计了一种机制,来让不同的server中的log保持一致。
Raft维护了下列属性
a. 在不同的logs中,如果两个entries有相同的index和term,则它们保存了相同的command。
b. 如果在不同的log中,两个entries有相同的index和term,那么这些logs之前所有的entries也保持一致。
属性一通过下列条件保证:
- 一个leader在一个给定的term中,一个log index最多只创建一个entry。
- log entries永远不会改变它们在log中位置。
属性二通过执行一个一致性检查来保证。
- 当发送一个AppendEntries RPC的时候,leader会包含比这个最新的entries的前一个index和term。如果follower在它的log中没有发现相同的index和term,就会拒绝这个最新的entries。
当一致性检查成功的时候,leader就会知道follower的log和它自己的log完全一致。
正常情况下,leader和follower中的log保持一致,但是当leader和follower cash的时候,会出现不一致的情况。
如下图,follower的log可能会和一个新的leader的log不一致。
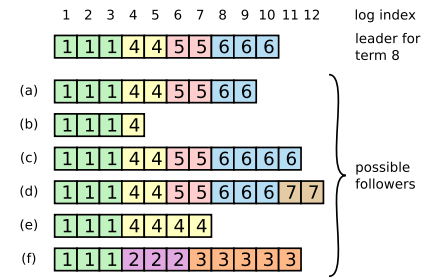
在Raft中,leader通过强制使follower复制它自己log的来处理这种不一致的情况。这意味着在follower logs中的冲突的entries会被重写。
为了让follower的日志和leader保持一致,Raft采取以下办法:
- leader找到最后一次两个log相同的点
- 然后删除那个点之后的日志,
- 并且发送给follower那个点之后leader的entries。
上诉这些动作发生在一致性检查的过程中。leader保存了每个follower的nextIndex,这个index是leader发送给follower的下一个log entry的index。当一个leader开始当选的时候,它初始化所有的nextIndex为它自己的logs的最新一个index。如果一个follower的log和leader不一样,一致性检查会失败。当失败之后,leader会逐渐减少nextIndex,直到到达一个点,leader和lfollower的日志是一样的。这时候,会移出follower的冲突的entries,然后追加来自leader的log entries。
有了这个机制,leader就不需要采取别的动作来回复日志一致。它仅仅只是开始正常的操作,日志会自动变得一致,当一致性检查失败的时候,leader永远不会重写或者删除它自己的log entries。